Kensu + Matillion: A Technical Deep Dive
Kensu is the first solution to bring advanced data observability capabilities to support Matillion, empowering organizations to gain richer insights into their data pipelines and ultimately strengthening trust and data productivity.
Matillion ETL is a popular tool for building and orchestrating data integration workflows. It simplifies extracting data from various sources, transforming it according to business requirements, and loading it into a cloud data platform. Matillion provides an intuitive visual interface and makes it easy for data teams to deliver business-ready data, with as much or as little code as they like.
Kensu has developed a Collector for Matillion capable of extracting data observations by connecting to Matillion API and the tables used in the job. The Kensu platform is a data observability solution providing comprehensive visibility into data pipelines, workflows, and flows. By integrating it with Matillion ETL, organizations can gain enhanced monitoring, auditing, and lineage capabilities, enabling them to better understand the flow of data within their ETL processes. This way, data teams have all the contextual insights necessary to understand where data incidents are coming from and what is the fastest way to solve them. Another significant benefit of using Kensu is the possibility of stopping data pipelines from working as soon as an incident occurs. This capability prevents flawed data from propagating and reaching end users.
How does the Kensu + Matillion Integration operate?
The Kensu collector for Matillion follows a series of four steps to collect, process, and aggregate the necessary data for observability and governance.
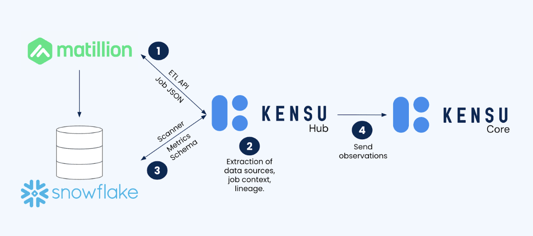
The first step, "Data Retrieval," involves the Collector retrieving the latest Matillion ELT API job runs data at regular intervals, ensuring observations are up to date. This continuous process captures the most recent changes in users’ Matilion data pipelines.
During "JSON Processing," the second step, the Collector processes the JSON response, extracting relevant information from the job run data, such as data sources, lineage details, and job run information, such as the project, environment name, and execution timestamp. Parsing and structuring the JSON data for further analysis are key actions during this processing, as they form the ultimate contextual information necessary for efficient observability and troubleshooting data reliability incidents.
Once the JSON Processing is complete, the third step, "Snowflake Querying,” begins. For each Snowflake data source identified in the job run data, the collector queries the corresponding Snowflake table to retrieve additional metadata regarding schema information, such as column names, data types, and a set of metrics. The observations collected may include metrics such as missing values, number of rows, and distributions (e.g., mean, min, max) for numerical columns. By fetching this additional information from Snowflake, the collector enriches the observations with valuable insights about the underlying data. This step allows the collection of metrics used to validate the data based on Kensu rules.
The final step, "Aggregation and Sending," commences after retrieving the necessary data from both the Matillion API and Snowflake. During this step, the collector aggregates and processes the collected information. It organizes the observations and aligns them with the appropriate job runs, data sources, and associated metadata. The collector sends the aggregated data to the Kensu core, where it can be utilized for comprehensive data observability, governance, and analysis.
The Kensu Circuit Breaker
Another central integration component is the Kensu Circuit Breaker, which halts an application if a specified data incident has been detected. This feature prevents flawed data from propagating and reaching end users.
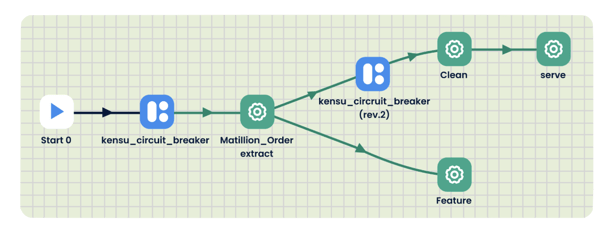
Data teams can enact different custom rules to trigger circuit breakers. The circuit breaker can act as a postcondition to validate a job or as a precondition to ensure the inputs of a job meet the requirements. For instance, a user can freeze an application if a schema change has been identified upstream. Once the circuit breaker has stopped the pipeline from working, data teams can leverage the contextual insights provided by Kensu to identify and tackle the data incident quickly.
Boost data team productivity with Kensu + Matillion.
As the first data observability solution to integrate with Matillion, Kensu enables data practitioners with all of the contextual information necessary to understand where data issues are coming from and what is the fastest way to solve them. It also prevents data issues from propagating toward end users by instantaneously and automatically stopping jobs from running.
The integration brings seamlessly advanced data observability capabilities to organizations, so they can harness the maximum potential of their data and deliver reliable insights to the business with maximum efficiency.
If you want to experience the Kensu integration with Matillion, book a demo with our team to discover how to get immediate control over your Matillion jobs’ data, or test our solution yourself with our free trial.