Why SLAs Are Critical to Ensuring Data Reliability.
As far back as the 1920s, Service Level Agreements (SLA) were used to guarantee a certain level of service between two parties. Back then, it was the on-time delivery of printed AR reports. Today, SLAs define service standards such as uptime and support responsiveness to ensure reliability.
The benefit of having an SLA in place is that it establishes trust at the start of new customer relationships and sets expectations. Customers feel confident they will get the level of service they require, and the provider knows which issues they are responsible for resolving. SLAs also provide specific metrics to measure the service provided as well as the remedies or consequences should the provider not meet the agreed-upon service levels.
This article will look at why data projects should include SLAs and how to structure them to facilitate better communication between parties, improve consumer satisfaction, and negotiate mutually agreed upon data quality standards that will help increase data reliability.
Why do you need an SLA for data projects?
Just as IT teams have found SLAs to be foundational to ensuring the reliability of the service a vendor provides, today's data teams need a similar guarantee of reliability. The data ecosystem is growing increasingly complex and difficult to manage. At the same time, the reliance on data by various lines of business has dramatically increased, making it more urgent and necessary that the data sources and data pipelines be reliable. But the longer and more complex the data chain becomes—and the more data producers and consumers there are—the greater the likelihood of issues.
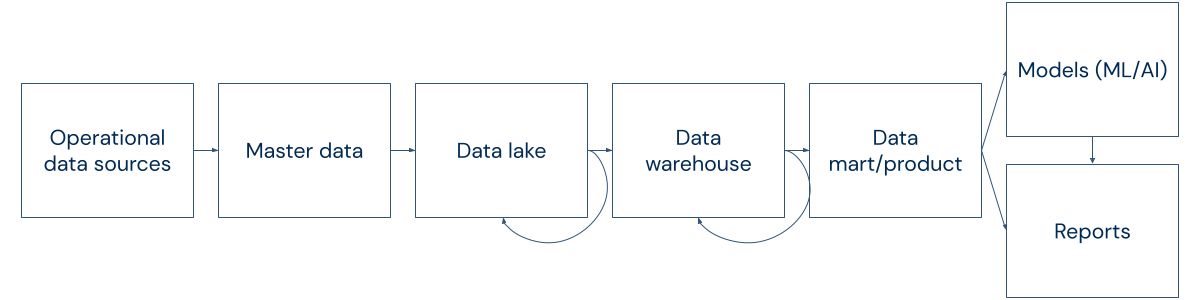
To better understand how these issues play out in the real world, let's look at one example of how a single dataset that is part of a long and complex data chain can result in multiple data issues.
Take one retail store's point of sale data, which multiple departments use for various analyses, including sales, finance, fraud, and marketing. If there is even a single small error in the data—whether that's in the freshness, completeness, consistency, or some other data quality dimension—the consequence is multiplied by the number of users relying on that single data set. Moreover, the more transformations there are between the original and final data, the more data pipelines are impacted and the more difficult troubleshooting the root cause of the failure becomes.
This is why nearly one-third of companies say their biggest challenge with data pipelines is the excessive time spent on break and fix. And why another quarter says that deploying error-free data pipelines is also a top challenge.
_
Biggest challenges with building and deploying data pipelines
-
30% say excessive time spent on break and fix
-
26% say data pipelines are too complex
-
25% say deploying error-free data pipelines
-
One of the reasons it's so difficult to resolve data issues is an asymmetry of communication and accountability between the data producers (usually the data engineering team) and data consumers (usually business users). Typically, the data producers believe it's the consumers’ responsibility to check the quality of the data they receive. However, the consumers believe that it's the data producers's responsibility to check the quality of the data they provide.
This misalignment in the perception of responsibility means neither side takes full responsibility for the data quality. Thus, no one is feeling responsible to take actions to anticipate or prevent data issues from occurring, or when they do occur both try to reject the responsibility on the others. There is a breakage in the conversation and mutual trust. So, when a data issue is identified, the impact is far-reaching. Incorrect analysis and insights may have been generated for some time, meaning the consumers may have been making decisions based on faulty data. And on the data producers side, troubleshooting and patching the issue now requires an excessive amount of time.
This dynamic would change if an SLA were a standard component of any data project. An SLA would establish the need for a formal discussion and mutual agreement on the expectations and capabilities of each party for any data issue, and it would create an understanding between both parties that the responsibility for data reliability needs to be both understood and shared.
By agreeing at the start of a data project on what each party's responsibility is when it comes to ensuring the quality of the data, there are numerous benefits:
- Clarity of expectations: An SLA provides increased awareness on the data producer team's part about how data quality will be evaluated by data consumers based on a specific set of KPIs. This pushes the data producers to prioritize these KPIs and take a more proactive approach to monitor the data to ensure these metrics are being met consistently.
- Greater trust: Data consumers will have greater trust in the data because they know that the data producers are monitoring the data to meet their expectations. Likewise, data producers have clear data KPIs to follow, giving them more confidence and trust that they are catching the right data issues and resolving them before the data reaches the consumer.
SLAs streamline communication and formalize agreement between data producers and data consumers about what metrics matter most. They ensure that data producers prioritize, standardize, and measure critical data reliability KPIs for a specific project to ensure its overall success.
How to define an SLA
SLAs may be contractual agreements, but they are built on a foundation of collaboration and mutually-agreed understanding. When executing an SLA, there are two key steps in the process:
1. Define the purpose
At the beginning of any data project, all project stakeholders, including data producers and data consumers, need to discuss the purpose of the data project and what data requirements are necessary to achieve the goal.
For example, if the data project is related to Customer Scoring, there needs to be an initial discussion around the purpose of the customer scoring. A bank's marketing team scoring customers to determine who will most likely respond to retargeting efforts with paid ads will have different data requirements than if the bank is trying to score customers to determine how much credit to lend them.
Having this discussion and understanding at the outset of a data project is crucial to helping data producers understand the impact of the data on the results. For instance, the marketing team may need near real-time data updates to accurately score and retarget customers within a few hours or days of their initial visit. But, in evaluating creditworthiness, the timeliness of the data may not be as critical.
An SLA also helps get everyone on the same page. Both data producers and consumers know what the main objective is of the project and what is required from the data to achieve it. And a formal SLA increases the commitment of both parties to meet their responsibilities.
Most importantly, if this step is skipped, data producers will not understand what is required to achieve data quality for the project and why certain types of data or data dimensions (freshness, completeness, accuracy, etc.) are important to the project. They will also not feel involved in defining the KPIs for the project and may even aggressively challenge them if they think it's a burden on them to meet these KPIs.
2. Align on data quality indicators
Once both parties understand the purpose of the data project, it's time to discuss what indicators will be necessary to ensure data quality. There are six standard dimensions data quality is measured on:
- Accuracy
- Completeness
- Consistency
- Timeliness
- Validity
- Uniqueness
Using these dimensions, data producers and consumers need to align on specific indicators of data quality based on the purpose of the data project. For instance, the accuracy of the data might be critical if the finance team wants to compare monthly retail sales between individual stores. In this case, data producers and consumers would agree on a low ratio of data to errors.
| Data Quality Dimension | Key Indicator | Examples |
| Accuracy | The data values should be reliably representative of the information. | Data about real current customers. |
| Completeness | The data should contain all the necessary and expected information. | All information about all customers. |
| Consistency | Data should be recorded in the same manner across all systems. | Contains calendar monthly average usage. |
| Conformity | Data should be collected in the same format. | Calendar monthly average usage is represented in thousands. |
| Integrity | Data must be connected to other data across all relationships and not be considered as an orphan. | Refers to the contract in the CRM using its correct id. |
| Timeliness | Data must be up to data, and it must be ingested at the correct intervals. | Refreshed weekly (Thursday max) with data of previous week. |
| Uniqueness | Data needs to be cleaned of duplicate entries. | Name and Address is unique unless professional contracts. |
As part of this process, both data producers and consumers must define the indicators. Data consumers may have a biased approach to data or may not completely understand the whole data chain. Therefore, they may make unrealistic demands, such as requesting that data be refreshed every hour when it only needs to be refreshed once a day. Consumers may also demand too many indicators, unnecessarily burdening the data producers. Consequently, the data producer needs to be able to weigh in on whether the indicators make sense and are possible.
It's also important for data producers to feel involved in the project. When the process is more collaborative, it results in more buy-in to diligently monitor the data quality based on the indicators agreed upon by both parties.
Implementing your data SLAs
Implementing a data SLA can't prevent every data issue in a complex data ecosystem. But, it can go a long way in reducing miscommunication, setting upfront expectations for both parties, and helping to ensure that the right data quality metrics are monitored from the outset—which will positively impact data reliability.
Next in this series: How SLOs can also provide a helpful framework for setting data quality metrics and building trust and a data-driven culture.