Data Mesh: Promoting Data as Products
The Data Mesh is a fascinating approach to designing and developing data architectures – and it’s generating a lot of attention and discussion in the data world.
The concept, introduced by Zhamak Dehghani, challenges the status quo idea of a centralized, monolithic data architecture. Instead, advocating for a decentralized domain-driven design.
While there are many aspects to the Data Mesh, this article will focus on one particularly important concept Dehghani raises: promoting data as a product.
Data as a product
The Data Mesh is not comprised of technologies or methods but organizing principles. These principles expand beyond data architecture, touching on several data management areas and multiple roles within an organization. This breadth of influence is one of the reasons we believe there is such enthusiasm for the Data Mesh.
Currently, within most organizations, data management is split into several areas following what is well-known as the DAMA data management model (see the figure below). Although these 10 areas of data management help organizations focus on specific challenges within data governance, they also tend to create silos between associated responsibilities.
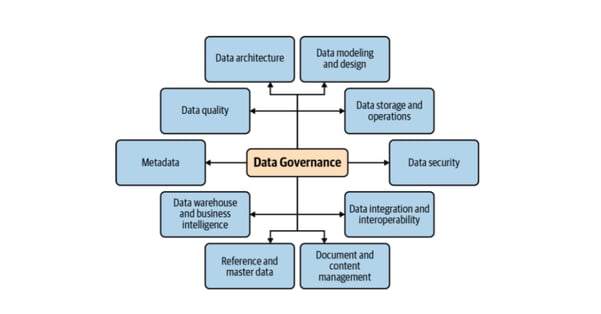
© Data Management Wheel (DAMA, What Is Data Governance? Understanding the Business Impact)
One of the biggest and most bizarre issues that results from this siloing in the data world is that consumers are responsible for validating the data they use. The Data Mesh helps to resolve this issue by treating data as a product and extending the responsibility of the data to the business domain.
In short, the business domain that created or generated the data manages it as it would any other products under its purview. For instance, an insurance company like Allstate Insurance would manage data similar to a new insurance policy or Disney would treat the data like its latest new movie release (i.e. as a product the business can monetize).
In a traditional, centralized data management environment, the responsibility of data ownership has chiefly fallen to the teams’ performing activities related to the technology, like the data warehouse team. But what the Data Mesh does is give back the responsibility to the business domain. Those who, according to Dehghani, “are most intimately familiar with the data, are first-class users of the data, and are already in control of its point of origin.” Hence, it becomes the business domain’s responsibility to deal with the data product's quality alongside its availability, robustness, and compliance.
Once the business domain has taken ownership of the data product, the next step is to promote or monetize that data product, just as they would other products within their responsibility.
Promoting data as a product
No product really sells itself. Even the most brilliant and useful products need sufficient awareness in order to sell successfully. Similarly, data as a product needs to be understood by its potential consumers.
Often with data, potential consumers (internal business users or external customers) have requested the data and they have primarily defined their needs for that data product. The domain, for its part, concentrates on creating trust with customers (e.g., defining service level objectives) about the product it manages. The good news is, from that point of view, the data is generating value. Thus, like IT can bill its services and machines, the domain can also include data products on its profit and loss (P&L) statement.
However, if you limit your data product to only the first few business users, it will look like what we call “a customized product,” which is the wrong approach for products in general, including data products.
Managing a product requires investments of time and resources, which means there needs to be a return on investment for these efforts. For data products, having the domain see a return on investment is even more important, as the investments and the value of the data are reported in the P&L statement. Thus, a domain must successfully promote data products in order to improve its P&L.
The initial use cases you define will be primarily used to promote the value of the data product. However, as your base of consumers increases, they will find other use cases with the data, which is key to growing your product’s footprint in the market.
Why it’s critical to know how your data product is used
Growing the product impact exposes the domain to a broader audience, and therefore increases the responsibility of ensuring the data’s quality.
Unconsciously or not, this can be the biggest blocker or reticence to considering data as a product, as no one likes to be exposed, at least without being appropriately equipped.
Let’s dig into this” blocker” a bit further and unveil the two underlying critical fears:- What if my product is misused? (e.g., Facebook and Cambridge Analytica scandal)
- What if I screw up? (e.g., I change my data and the CFO uses it for the annual report creating major inaccuracies in the report)
Because being responsible for a product means the domain must also be able to respond to all situations associated with their data, it can feel inherently risky. Yet, consumers of the data often bear those same risks and worries – that the data they’re consuming may be inaccurate.
However, this is not an excuse to give up. Instead, you need to create an open and transparent bilateral communication flow between the domain and the consumers. This includes providing
- Service level objectives (SLOs): Because an SLO spells out simply and clearly what metrics the domain is responsible for and what they’ll be measured against, consumers know which data catastrophes are within their responsibility as well.
- Context: The domain is always aware of new or updated usage of their product (use cases, applications, projects, etc.). This reduces the frustration linked to any unknowns.

Information flow between domain and consumers
Because the number of consumers and usages will scale, creating and maintaining this flow manually will increase costs and lower the productivity of both the domain and consumers. Therefore, we recommend, as much as is possible, this information be generated automatically, persistently, and accessible directly from all data applications and tools.
With these aspects in place, the domain now has an opportunity to hack the growth of its product.
Creating awareness about the different data product use cases
Typical data catalogs are used to find data. As they are usually composed of a descriptive metadata repository (the type of columns, lineage references, etc.) and glossaries, they consider data features as first-class citizens.
Therefore, with data catalogs, end users can easily get to the data they are looking for. However, it is not sufficient to find the data they are searching for.
Here’s an analogy with Google to make this point clearer.
Google search can be used as a shortcut for a specific website you have in mind or a specific topic, such as searching “Gmail” or “price of a Tesla.” Google will get you to this specific content quite easily.
You can also use Google to find content, (e.g., website, PDF, document, data, etc.) about the information you are searching for. For instance, by searching for “online mailbox” or “costs of electric cars,” you’ll be recommended the same websites as your previous search. However, you may not have been aware of these websites yet, which makes you feel that you’ve “discovered” them.
What a search engine is able to do is to recommend the right content to match your needs. But it doesn’t stop there. The search engine can also recommend associated research, which allows you to “discover” alternative ways to achieve your goals.
 This is possible because such catalogs (Google search is a catalog) can leverage the relationship between content and the queries. More importantly, data catalogs provide information from the complex graphs they are forming to shed light on the underlying use cases and goals.
This is possible because such catalogs (Google search is a catalog) can leverage the relationship between content and the queries. More importantly, data catalogs provide information from the complex graphs they are forming to shed light on the underlying use cases and goals.
As a result, data catalogs are evolving towards the usage of so-called active metadata — information about “how is the data used and what for.” This is the “context information” that consumers must provide to the domain, which we discussed in the previous section.
For the Data Mesh, which is composed of several data products (see figure below) the contextual information is composed of both the information about data intelligence applications and their participation in larger projects (i.e., business use cases).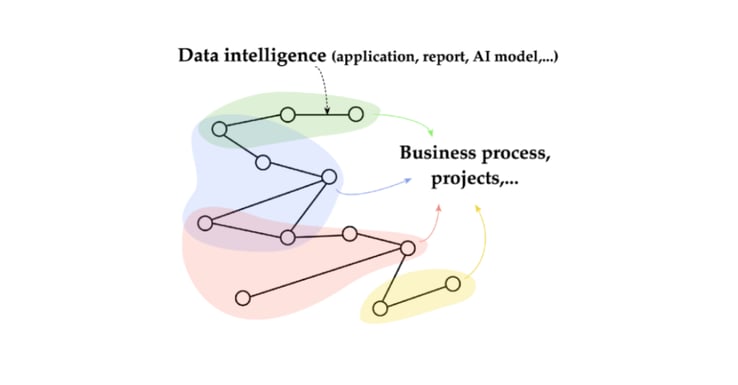
Data Mesh — Data as Products — Applications — Projects
Therefore, a search engine can use this context to recommend data products to potential new consumers due to queries having similarities to known use cases. Companies that want to become data-driven must enable such capabilities to scale their organization.
As you can read in Dehghani’s book, the context (business needs, code, system, etc.) is one of the important components of the Data Mesh. And how you leverage that context will define your success in implementing the Data Mesh within your organization.
What’s next
We are only scratching the surface of Data Mesh's capabilities in this post. If you wish to dive deeper, we highly recommend reading Dehghani’s book.
Also, if you wish to simplify and automate the control of your data for different business domains, we recommend reading our post on DODD or contacting our team to learn about the Data Observability Driven Development (DODD) method.